
神社の狛犬と競い合っている柴犬でした。
10歳になっても頑張るぞと言っているようです。
さて、今回は連番を振るSQLをACCESSで考えてみました。
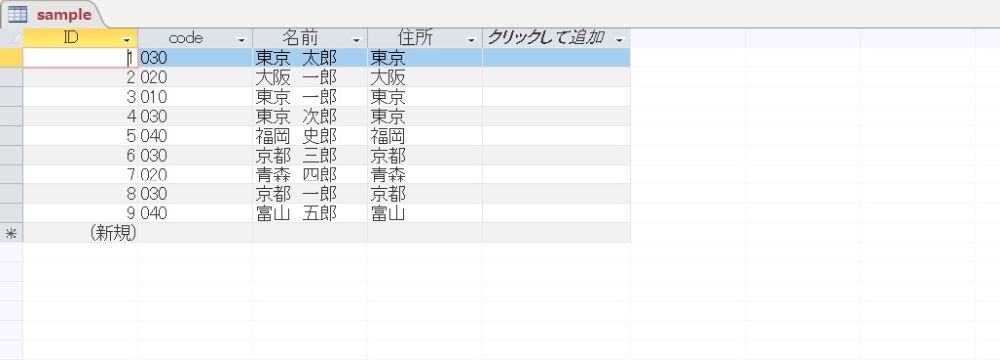
テーブルとデータ
まず、テーブルの構造とデータは次のようなものを考えます。

次に、データです。
このデータを条件 code = ‘030’ で抽出して、名前の小さい順に並べ替え、1 から順に番号(順番)を振ります。
クエリーの作成・実行
次のようなクエリーをデザインビューではなくSQLビューで書きます。
というのは、デザインビューでは作成できません。

サブクエリーが幾重に入れ子になって、複雑な SQL 文になりました。
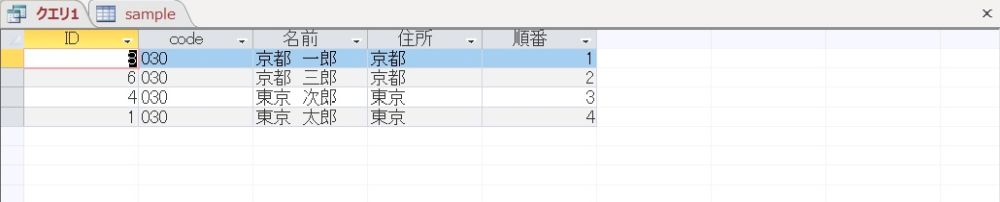
早速、実行してみました。
無事、想定の結果が得られました。
SQL
SELECT
Y.*
FROM
(SELECT
A.ID
, A.code
, A.名前
, A.住所
, (SELECT
Count(*)
FROM
(SELECT
C.*
FROM
sample AS C
WHERE
C.CODE='030') AS B
WHERE
A.名前 >= B.名前) AS 順番
FROM
(SELECT
D.*
FROM
sample AS D
WHERE
D.CODE='030') AS A) AS Y
ORDER BY Y.順番;
名前がユニークな集合でない場合
上のデータは名前がユニークな集合ですが、次にユニークではない集合、たとえば次の例を考えます。
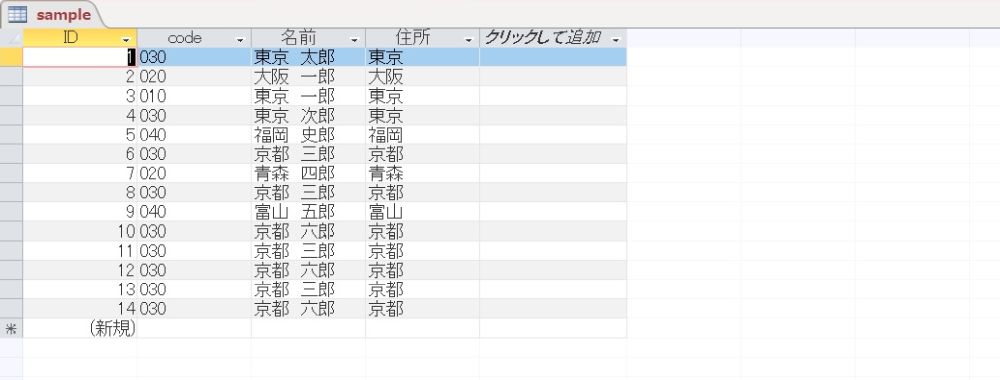
このデータに上と同じクエリーを実行してみますと、次のようになります。
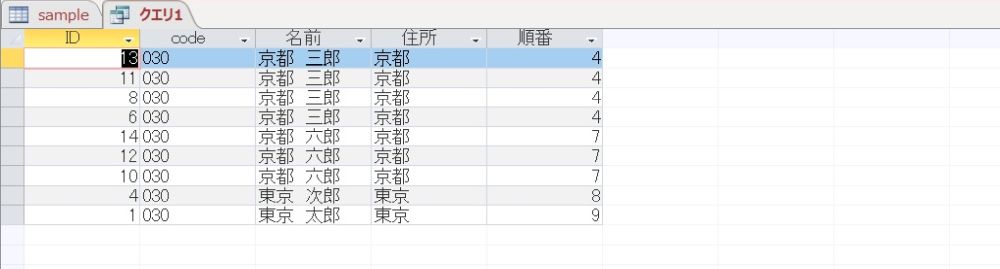
やはり、「京都 三郎」は 1 としたいです。
クエリーの改良
それでは、「京都 三郎」は 1 、「京都 六郎」は 5 としたい場合、どうしたらよいのか考えてみます。
SELECT Y.*
FROM (SELECT
A.ID
, A.code
, A.名前
, A.住所
, (SELECT
Count(*) + 1
FROM
(SELECT
C.*
FROM
sample AS C
WHERE
C.CODE='030') AS B
WHERE
A.名前 > B.名前) AS 順番
FROM
(SELECT
D.*
FROM
sample AS D
WHERE
D.CODE='030') AS A) AS Y
ORDER BY Y.順番;
この SQL は、「 Count(*) 」を「 Count(*) + 1 」に、「 A.名前 >= B.名前 」から「 A.名前 > B.名前 」に変更しただけです。
変更した SQL の実行
早速、実行してみます。
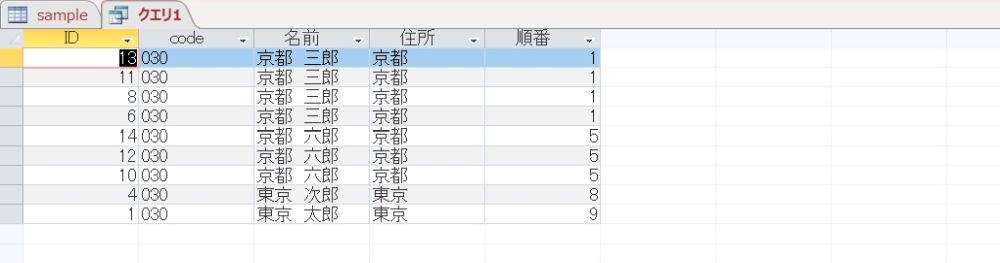
想定した結果が得られました。
同一人の複数の表示が気になる
「京都 三郎」順位 1 が4レコード、「京都 六郎」順位 5 が2レコードの表示があるのを、同一人であるから1レコードにしたい。
名前の集合をユニークにすればよいので、名前をグループ化します。
SELECT Y.*
FROM (SELECT
A.ID
, A.code
, A.名前
, A.住所
, (SELECT
Count(*) + 1
FROM
(SELECT
MAX(C.ID) AS ID
, MAX(C.code) AS code
, C.名前
, MAX(C.住所) AS 住所
FROM
sample AS C
WHERE
C.CODE='030'
GROUP BY C.名前) AS B
WHERE
A.名前 > B.名前) AS 順番
FROM
(SELECT
MAX(D.ID) AS ID
, MAX(D.code) AS code
, D.名前
, MAX(D.住所) AS 住所
FROM
sample AS D
WHERE
D.CODE='030'
GROUP BY D.名前) AS A) AS Y
ORDER BY Y.順番;
これを実行してみます。
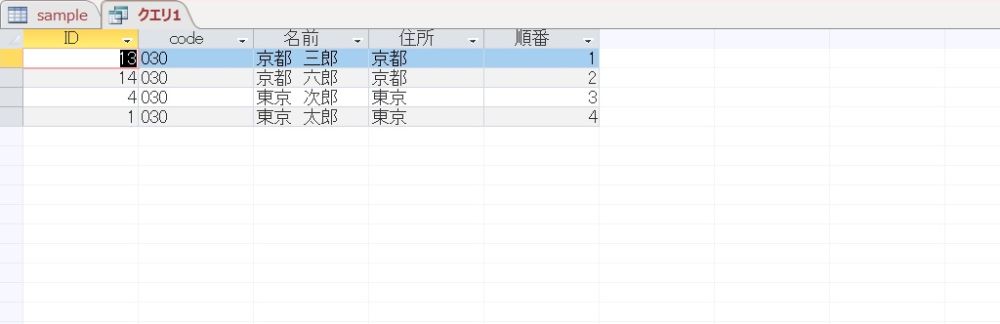
想定した結果が得られました。
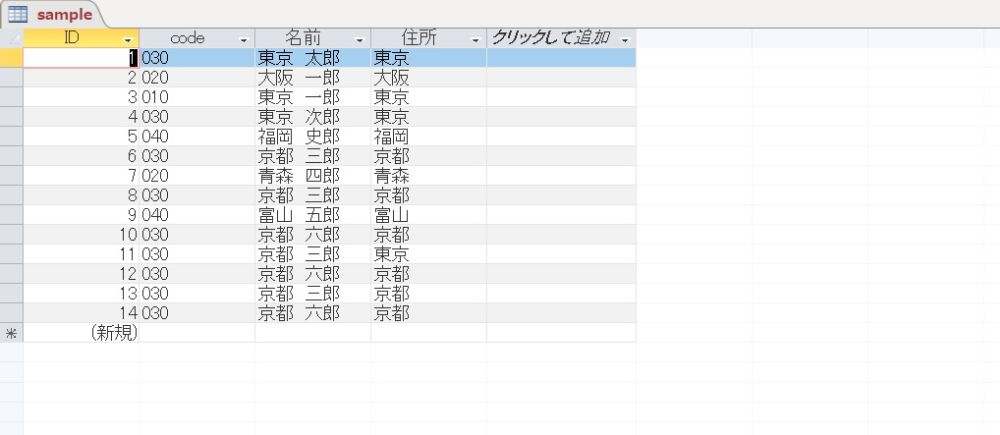
同性同名に対応する
同性同名の別人があるデータを考えてみます。
次のデータでは、IDが 11 と 13 の「京都 三郎」の住所はそれぞれ「東京」「京都」で同性同名の別人です。
このような場合の SQL を考えてみます。
ユニークなデータの比較が出来ればよいはずです。
名前と住所を結合してユニークな集合を作り比較することにします。
SELECT Y.*
FROM (SELECT
A.ID
, A.code
, A.名前
, A.住所
, (SELECT
Count(*) + 1
FROM
(SELECT
MAX(C.ID) AS ID
, MAX(C.CODE) AS code
, MAX(C.名前) AS 名前
, MAX(C.住所) AS 住所
, C.名前住所
FROM
(SELECT
E.*
, E.名前 & E.住所 AS 名前住所
FROM
sample AS E
WHERE
E.CODE='030') AS C
GROUP BY C.名前住所) AS B
WHERE
A.名前住所 > B.名前住所) AS 順番
FROM
(SELECT
MAX(D.ID) AS ID
, MAX(D.CODE) AS code
, MAX(D.名前) AS 名前
, MAX(D.住所) AS 住所
, D.名前住所
FROM
(SELECT
F.*
, F.名前 & F.住所 AS 名前住所
FROM
sample AS F
WHERE
F.CODE='030') AS D
GROUP BY D.名前住所) AS A) AS Y
ORDER BY Y.順番;
かなり長文の SQL になりましたが実行してみます。
ところで、MAX 関数を使ったのは、ORDER BY 句の記述を簡単にしたいからです。
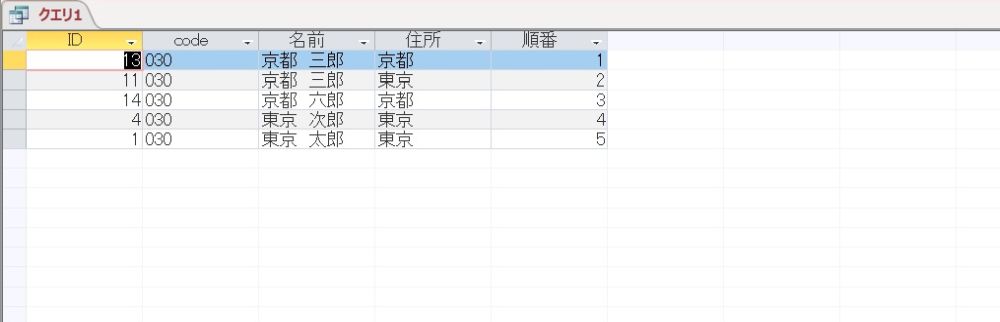
これも想定とおりの結果が得られました。