また何かをしているなという顔をしている柴犬です。
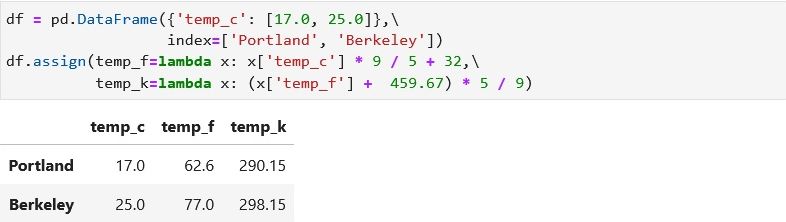
Pandas を使って縦持ちの表を横持ちすることをしてみました。
JupyterLab を使って即時にコードを書いて実行、結果を直ぐに確認することができるので、Python – Pandas – JupyterLab の組み合わせはすごいです。
「コードを書いて実行、結果」このループの素早さの快感を改めて実感しました。
概要
Pandas を使って縦持ちの表を横持ちすることをしてみました。
最後のピボットを使うところは同じですが、そこに至る前処理にいろいろな方法があります。
ひとつつの関数にいろいろな引数、返しがあり混乱するところでもあります。
作成
データ例
データ例はつぎのとおりです。
まずは、データフレームに読み込みます。
import pandas as pd
import numpy as np
data = [
{'city': 'tokyo', 'date': '2023-02-03'},
{'city': 'tokyo', 'date': '2023-02-04'},
{'city': 'tokyo', 'date': '2023-02-05'},
{'city': 'kyoto', 'date': '2023-03-01'},
{'city': 'oosaka', 'date': '2023-03-04'},
{'city': 'oosaka', 'date': '2023-03-05'},
{'city': 'kyoto', 'date': '2023-03-05'},
{'city': 'kyoto', 'date': '2023-04-02'},
]
data = pd.DataFrame(data)
jupyter lab で実行してみます。
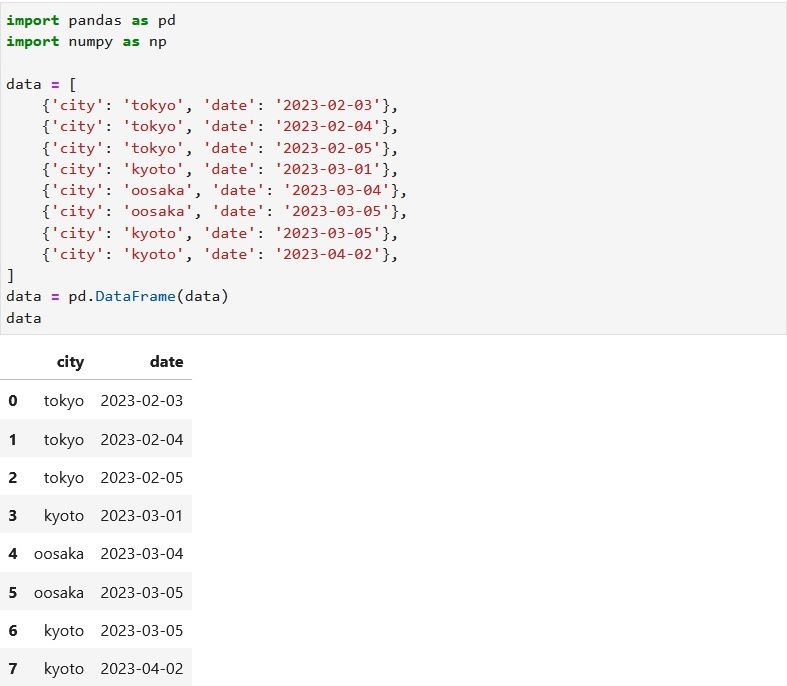
横もちにする列名の作成
グループ毎に 0 から始まる番号を振り、「date_」を先頭に付加したものを列名とします。
この場合「city」をグループにして、列名は date_1、date_2・・・・となります。
datatemp = (
data
.groupby(['city'])
.apply(lambda x: pd.Series(np.arange(len(x)), x.index))
.map('date_{}'.format)
.reset_index(name = 'newid')
)
datatemp
jupyter lab で実行してみます。
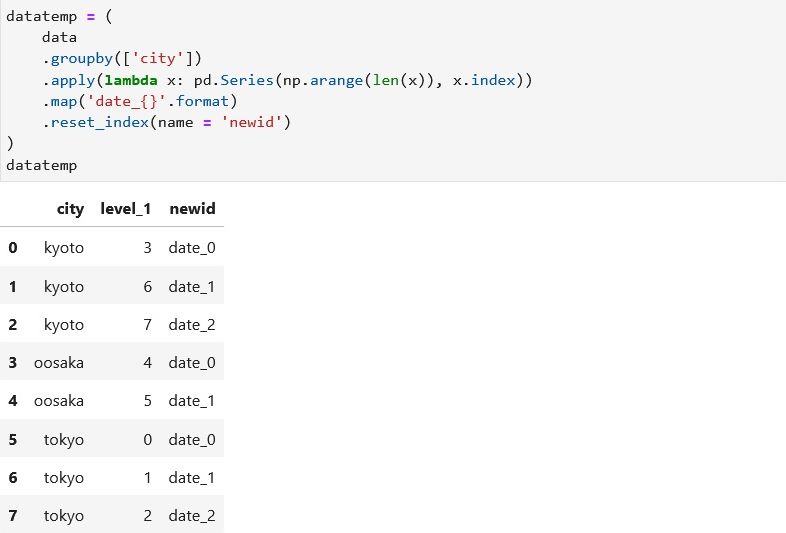
データフレームの結合
データフレーム「data」の index をキーとし、データフレーム「datatemp」の level_1 をキーとして結合します。
result = (
data
.merge(datatemp, left_index = True, right_on = 'level_1',\
how = 'left', suffixes=('', '_y'))
)
result
jupyter lab で実行してみます。
ピボットの作成
下準備ができましたので、ピボットを行います。
reset_index はインデックスを振り直し、rename_axis は 「city」左横を空白にします。
(
result
.pivot(index = 'city_x', columns = 'newid', values = 'date')
.reset_index()
.rename_axis(None, axis = 'columns')
)
jupyter lab で実行してみます。
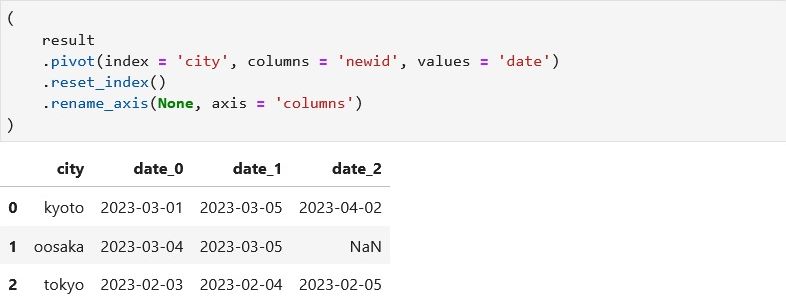
目的の表が得られました。
別の方法
Groupby、Lambda 関数の周辺を考え直して、ひとつの道が見えましたので追記します。
前の次の2つのパーツを1つにします。
datatemp = (
data
.groupby(['city'])
.apply(lambda x: pd.Series(np.arange(len(x)), x.index))
.map('date_{}'.format)
.reset_index(name = 'newid')
)
datatempresult = (
data
.merge(datatemp, left_index = True, right_on = 'level_1',\
how = 'left', suffixes=('', '_y'))
)
result次のようにひとつにします。
data['newid'] = (
data
.groupby(['city'], group_keys = False)['city']
.apply(lambda x: pd.Series(np.arange(len(x)), x.index))
.map('date_{}'.format)
)
data
jupyter lab で実行してみます。
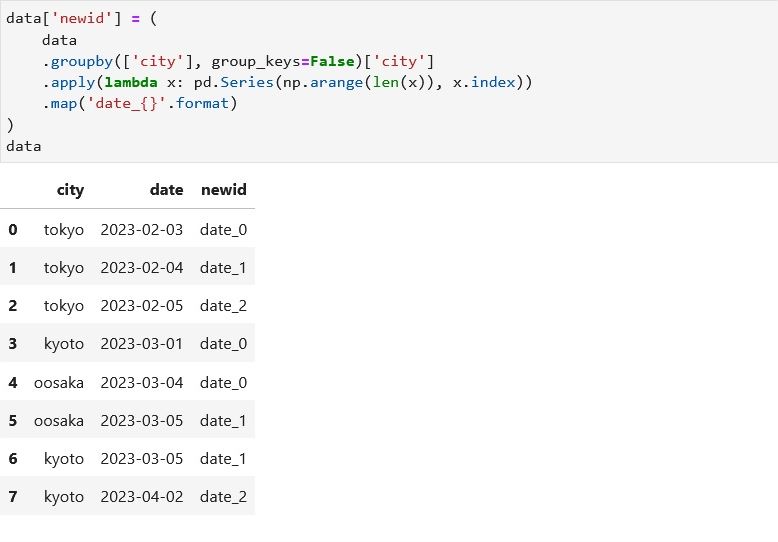
最後のピボットも次のように修正します。
(
data
.pivot(index = 'city', columns = 'newid', values = 'date')
.reset_index()
.rename_axis(None, axis = 'columns')
)mapを使わない別な方法
data['A'] = (
data
.groupby(['city'], group_keys=False)['date']
.apply(lambda x: pd.Series(range(len(x)), x.index))
)
def func(row):
return f'date_{row.A}'
data['newid'] = data.apply(func, axis = 1)
data
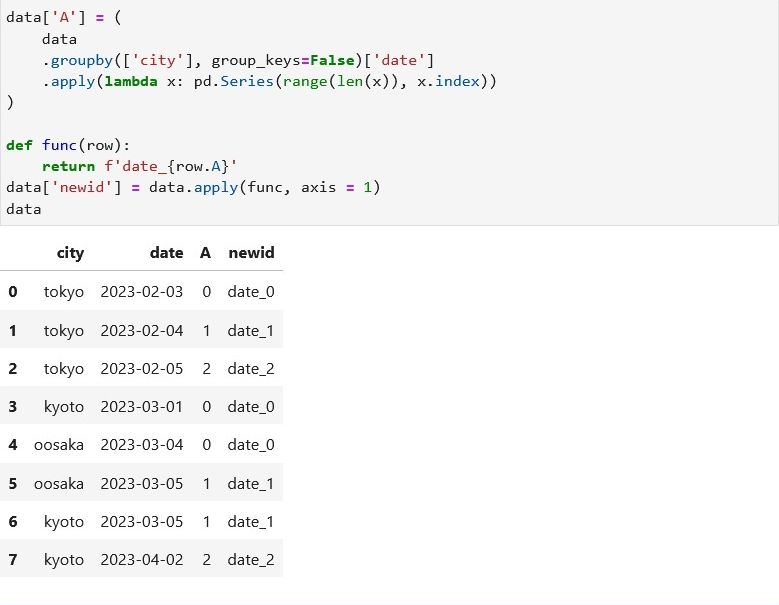
もっと簡単な方法があった
google で 「pandas グループごとに連番」 と検索してみると、cumcount 関数を使用した記事がいくつも出てきます。
cumcount 関数の戻り値は 、グループ毎の格要素のシーケンス番号の Series です。
その使い方は、次のとおりです。
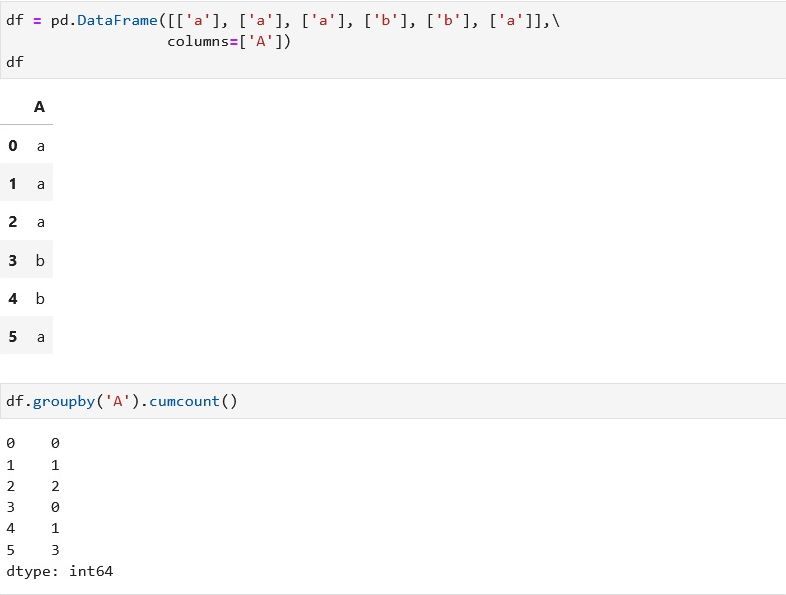
cumcount の使用
cumcount 関数を使ってみます。すごく簡素になります。
メソッドチェーンでたったの1行で済みます。
import pandas as pd
import numpy as np
data = [
{'city': 'tokyo', 'date': '2023-02-03'},
{'city': 'tokyo', 'date': '2023-02-04'},
{'city': 'tokyo', 'date': '2023-02-05'},
{'city': 'kyoto', 'date': '2023-03-01'},
{'city': 'oosaka', 'date': '2023-03-04'},
{'city': 'oosaka', 'date': '2023-03-05'},
{'city': 'kyoto', 'date': '2023-03-05'},
{'city': 'kyoto', 'date': '2023-04-02'},
]
data = pd.DataFrame(data)
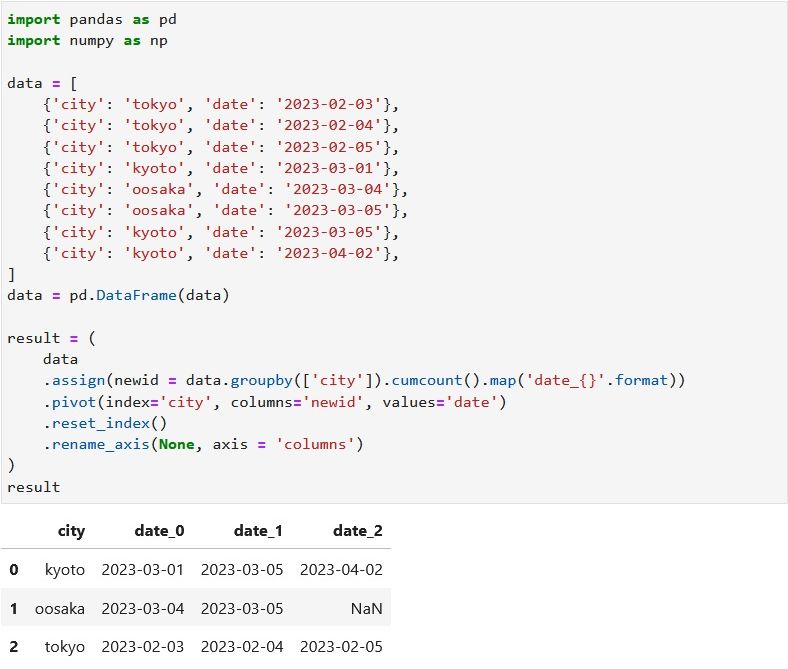
result = (
data
.assign(newid = data.groupby(['city']).cumcount().map('date_{}'.format))
.pivot(index = 'city', columns = 'newid', values = 'date')
.reset_index()
.rename_axis(None, axis = 'columns')
)
result
jupyter lab で実行してみます。
別の表現
result = (
data
.assign(newid = data.groupby(['city']).cumcount().map('date_{}'.format))
.pivot(index = 'city', columns = 'newid', values = 'date')
.reset_index()
.rename_axis(None, axis = 'columns')
)上記の部分を次のようにすることもできます。
見通しがいいので、こちらの方が私の好みです。
newid = (
data
.groupby(['city'])
.cumcount()
.map('date_{}'.format)
)
result = (
data
.assign(newid = newid)
.pivot(index='city', columns='newid', values='date')
.reset_index()
.rename_axis(None, axis = 'columns')
)newid = newid とするのは、参照の式とするためです。
assign について
既存の列に加えて、新しい列を持つ新しい DataFrame を作成します。
別の列に依存する場合であっても、同じ割り当てのなかで列を作成できます。
使い方は次のようになります。