
あけましておめでとうございます。今年も1年元気で過ごすぞ。ときりっとした顔で言っているようです。
概要
C言語でソートに挑戦することにしました。
成し遂げられるのか分かりませんがとにかくやってみます。
CSVファイルの読み込みを確かめる。
読み込んだデータを配列(構造体)にセットする。
ソートは次回とします。
C言語 マニュアル
私が今回参考にしたC言語マニュアルです。
いずれも非常に分かりやすい文書と例文で書かれています。
ありがとうございました。
https://manpages.ubuntu.com/manpages/kinetic/ja/man3/https://programming-place.net/ppp/index.htmlhttps://www.ibm.com/docs/ja/iファイルを読み込み後、ファイルの作成
とっかかりのコードです。
一文字毎に取り出しファイルに書き込むということをしています。
本来は、1字毎に読み取ってバイト数の判定して処理するのでしょうが、文字の扱いが難しいそうです。
ちょっと大変そうなので別の方法を模索します。
#include <stdio.h>
#include <wchar.h>
int main()
{
FILE *fin;
FILE *fout;
wint_t wc;
fin = fopen("./input.csv", "r");
fout = fopen("./output.csv", "w");
while ((wc = fgetwc(fin)) != WEOF){
wprintf(L"%ls\n", wc);
fputwc(wc, fout);
}
fclose(fin);
fclose(fout);
printf("File has been created...\n");
return 0;
}
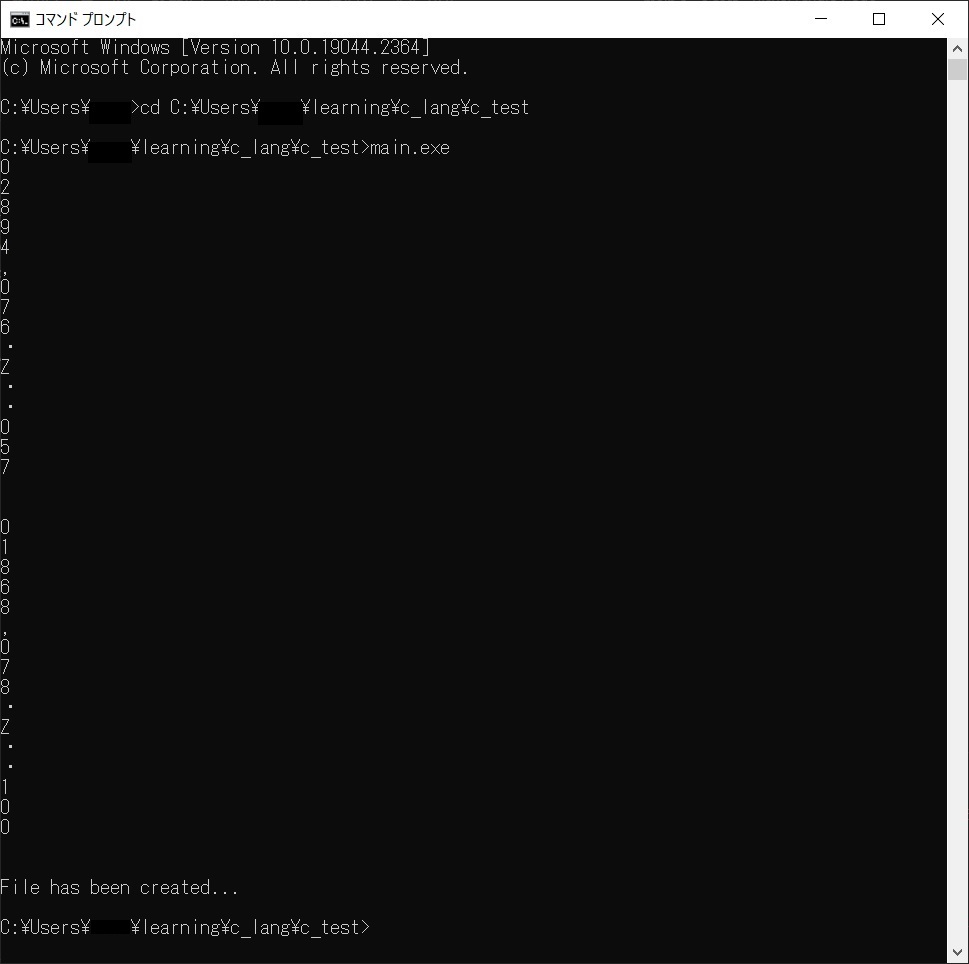
上のコードの実行結果です。
バイト単位で表示しているようです。
次に取り組んだのが、一行毎にバッファに取り込みセパレート文字で分離するという方法です。
試行錯誤して落ち着いたのが次のコードです。
こちらの方が何とか進めれそうなのでこれで行くことにします。
#include <stdio.h>
#include <stdlib.h>
#include <wchar.h>
#include <locale.h>
int main()
{
FILE *fin;
FILE *fout;
wchar_t *wc;
setlocale(LC_CTYPE, "");
fin = fopen("./input.csv", "r");
fout = fopen("./output.csv", "w");
const wchar_t *const separator = L",";
for (;;)
{
wchar_t str[90];
if (fgetws(str, sizeof(str) / sizeof(str[0]), fin) == NULL)
{
if (feof(fin))
{
/* ファイルの終わり */
break;
}
else
{
fputs("エラーが発生しました。\n", stderr);
exit(EXIT_FAILURE);
}
}
wchar_t *token = wcstok(str, separator);
while (token != NULL)
{
wprintf(L"%ls\n", token);
token = wcstok(NULL, separator);
}
fwprintf(fout, L"%ls", str);
}
fclose(fin);
fclose(fout);
printf("\nFile has been created...\n");
return 0;
}
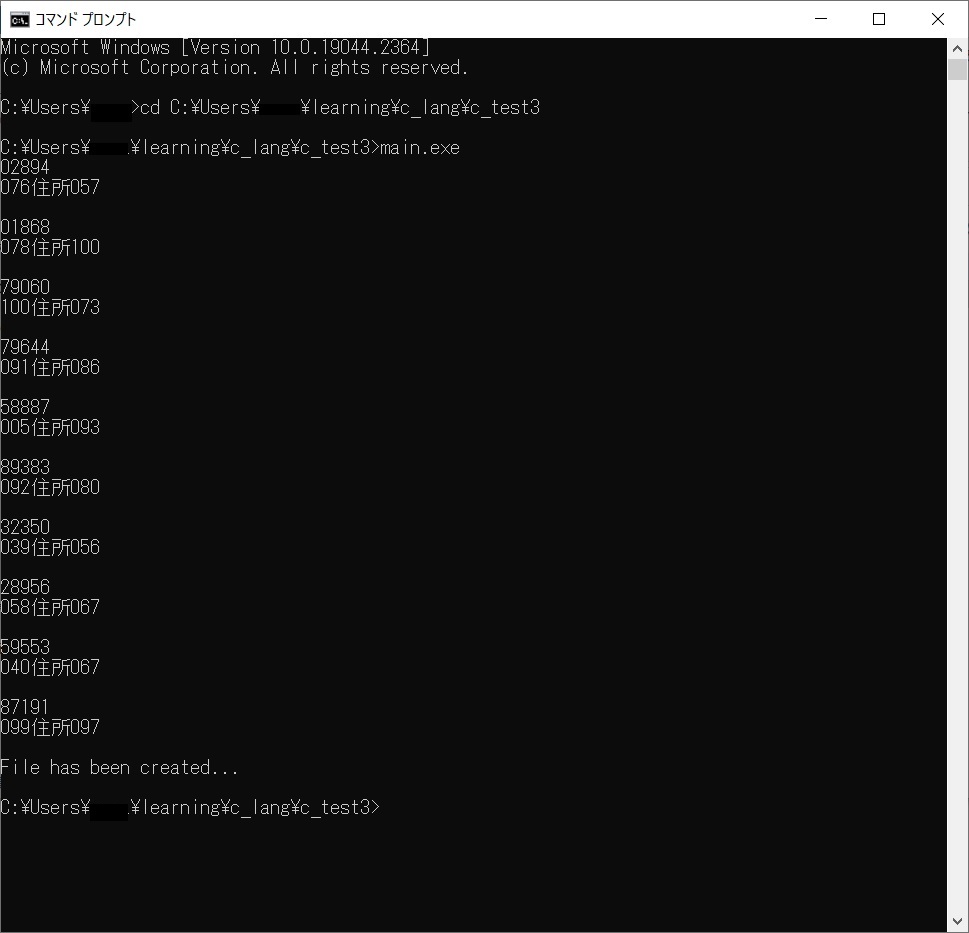
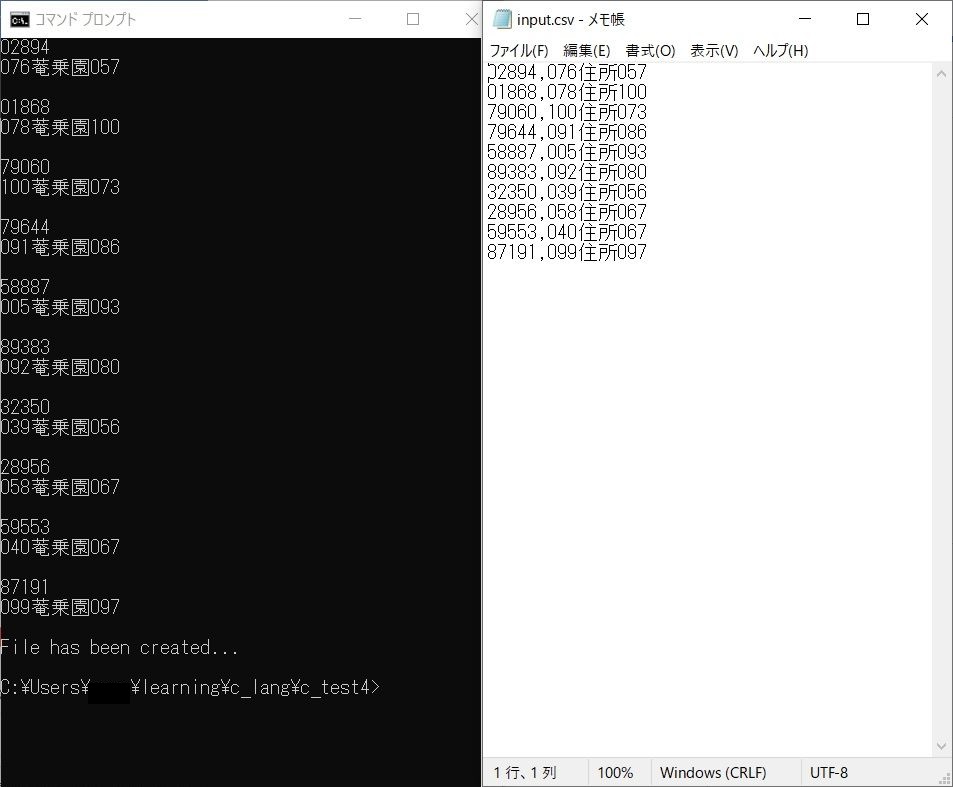
上のコード実行結果です。
セパレータで綺麗に分離されており、文字もきちんと表示しています。
wcstok カンマ区切りで分離
IBM i 資料の wcstok の解説の中にあるコードを手直ししてみました。
参考にしたC言語マニュアルにも wcstok の第三引数 &work があるのですが、私の使っているコンパイラーでは引数が多すぎますとエラーになります。
ですので、第三引数 &work をカットして使ってみましたが、今回の使い方で特に問題はないようです。
#include <stdio.h>
#include <wchar.h>
int main(void)
{
static wchar_t str1[] = L"?a??b,,,#c";
static wchar_t str2[] = L"\t \t";
wchar_t *t;
/* IBM等 とは違うようです。
/* wchar_t *ptr1, *ptr2; */
/* &work(&ptr1 &ptr2) をカットして順番を入れ替えました。 */
t = wcstok(str1, L"?"); /* t points to the token L"a" */
wprintf(L"t = %ls\n", t);
t = wcstok(NULL, L","); /* t points to the token L"?b" */
wprintf(L"t = %ls\n", t);
t = wcstok(NULL, L"#,"); /* t points to the token L"c" */
wprintf(L"t = %ls\n", t);
t = wcstok(str2, L" \t,"); /* t is a null pointer */
wprintf(L"t = %ls\n", t);
t = wcstok(NULL, L"?"); /* t is a null pointer */
wprintf(L"t = %ls\n", t);
return 0;
}
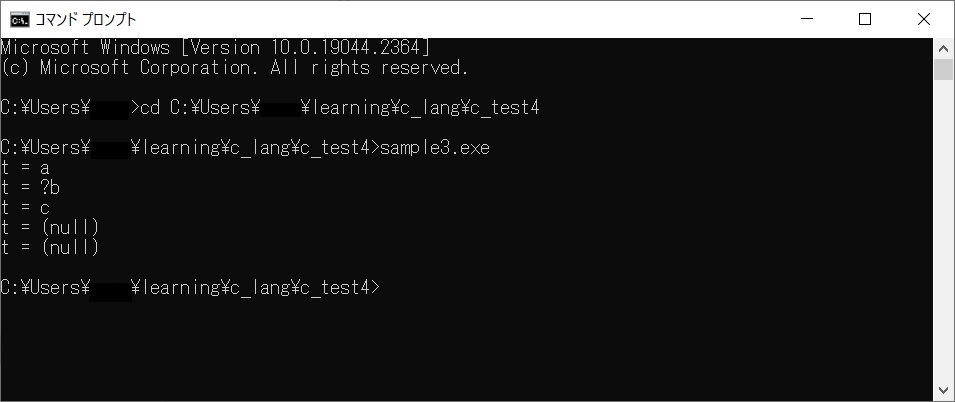
上のコードの実行結果です。
想定通りになっています。
2次元配列(構造体)に格納
変更前のトークン部分です。
wchar_t *token = wcstok(str, separator);
while (token != NULL)
{
wprintf(L"%ls\n", token);
token = wcstok(NULL, separator);
}このようにしたいので、全体的に見直したコードが下のようになりました。
wchar_t *token = wcstok(str, separator);
while (token != NULL)
{
/* wprintf(L"%ls\n", token); */
if (f == 0)
{
res = wcsncpy(record[count].f1, token, 20);
}
else
{
res = wcsncpy(record[count].f2, token, 30);
}
f += 1;
token = wcstok(NULL, separator);
}#include <stdlib.h>
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
int main()
{
FILE *fin;
FILE *fout;
wchar_t *res;
int f;
setlocale(LC_CTYPE, "");
fin = fopen("./input.csv", "r");
fout = fopen("./output.csv", "w");
const wchar_t *const separator = L",";
struct records
{
char f1[40];
char f2[50];
};
struct records record[1000];
int count = 0;
for (;;)
{
wchar_t str[90];
f = 0;
if (fgetws(str, sizeof(str) / sizeof(str[0]), fin) == NULL)
{
if (feof(fin))
{
/* ファイルの終わり */
break;
}
else
{
fputs("エラーが発生しました。\n", stderr);
exit(EXIT_FAILURE);
}
}
wchar_t *token = wcstok(str, separator);
while (token != NULL)
{
/* wprintf(L"%ls\n", token); */
if (f == 0)
{
res = wcsncpy(record[count].f1, token, 20);
}
else
{
res = wcsncpy(record[count].f2, token, 30);
}
f += 1;
token = wcstok(NULL, separator);
}
wprintf(L"%ls\n", record[count].f1);
wprintf(L"%ls\n", record[count].f2);
fwprintf(fout, L"%ls", str);
count += 1;
}
fclose(fin);
fclose(fout);
printf("\nFile has been created...\n");
return 0;
}
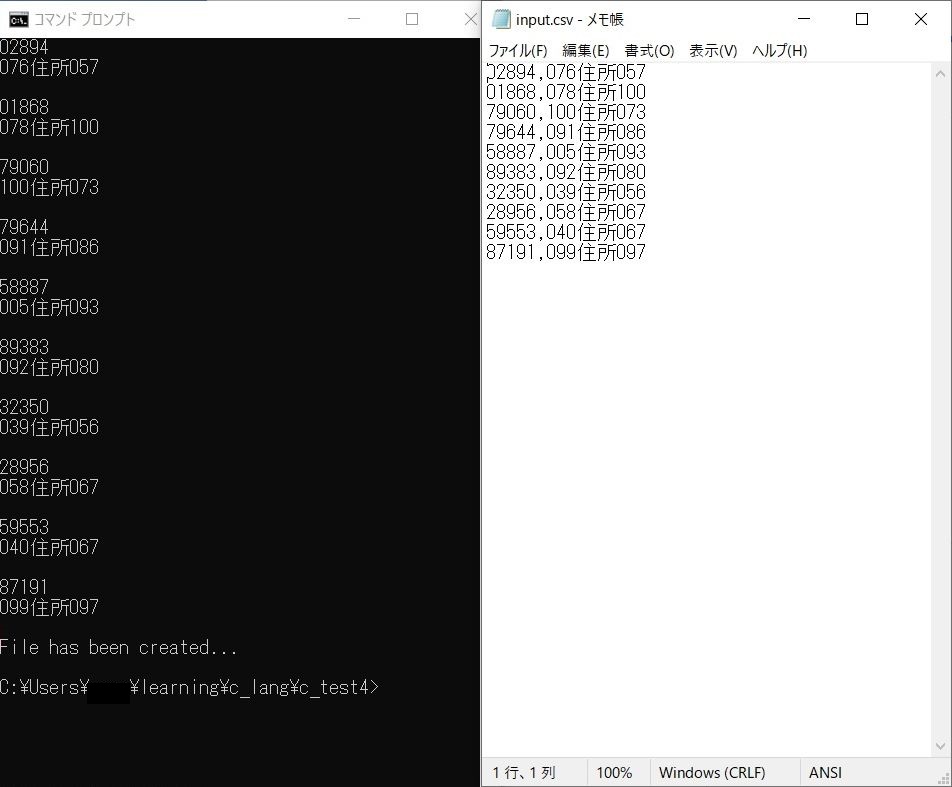
上のコードを実行してみました。
input.csv の文字コードが Shift_JIS ならば文字化けもなくコンソールに表示されます。
しかし、文字コードが UTF-8 ですと、次に示すように文字化けします。
3バイト文字をうまく処理する方法を考えなければなりませんが、今回はShift_JIS のファイル作成を目的としますので、UTF-8からShift_JIS のデコード、逆のエンコードを考えません。
100万件の読み込みができない
不覚でした。関数内で大きな配列を作ることは不適切のようです。
2000件でチェックしていたのですが、大きなデータにしたらメモリ不足で止まりました。
一時しのぎですが、次のように構造体の定義、作成をグローバルにしました。
#include <stdlib.h>
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
/* ここから外に出した部分 */
#define N 1200000
struct records
{
char f1[40];
char f2[50];
};
struct records record[N];
/* ここまで */
int main()
{
FILE *fin;
FILE *fout;
wchar_t *res;
int f;
setlocale(LC_CTYPE, "");
fin = fopen("./input.csv", "r");
fout = fopen("./output.csv", "w");
const wchar_t *const separator = L",";
int count = 0;
for (;;)
{
wchar_t str[90];
f = 0;
if (fgetws(str, sizeof(str) / sizeof(str[0]), fin) == NULL)
{
if (feof(fin))
{
// ファイルの終わり
break;
}
else
{
fputs("エラーが発生しました。\n", stderr);
exit(EXIT_FAILURE);
}
}
wchar_t *token = wcstok(str, separator);
while (token != NULL)
{
if (f == 0)
{
res = wcsncpy(record[count].f1, token, 20);
}
else
{
res = wcsncpy(record[count].f2, token, 30);
}
f += 1;
token = wcstok(NULL, separator);
}
/* wprintf(L"%ls\n", record[count].f1); */
/* wprintf(L"%ls\n", record[count].f2); */
fwprintf(fout, L"%ls\n", str);
count += 1;
}
fclose(fin);
fclose(fout);
wprintf(L"%ls\n", record[count - 1].f1);
wprintf(L"%ls\n", record[count - 1].f2);
printf("\nFile has been created...%d\n", count);
return 0;
}
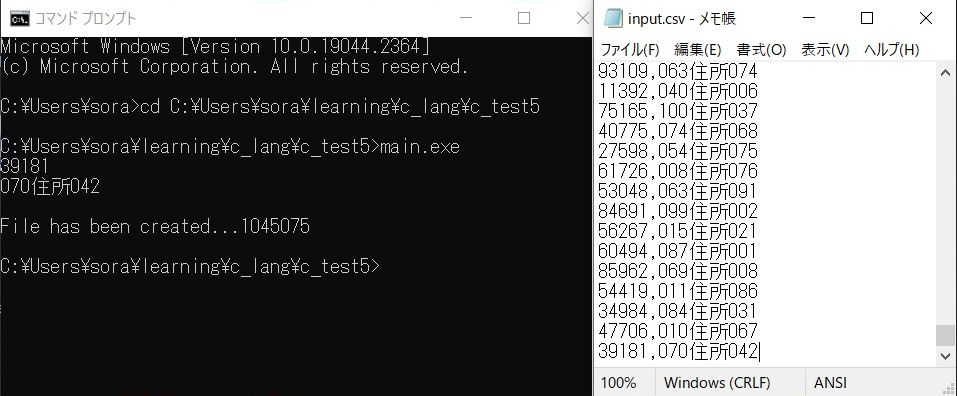
上のコードを実行してみました。
時間にして1秒足らずに読み込みました。期待できそうです。
今日の投稿はここまでとします。